Anonymous Authors
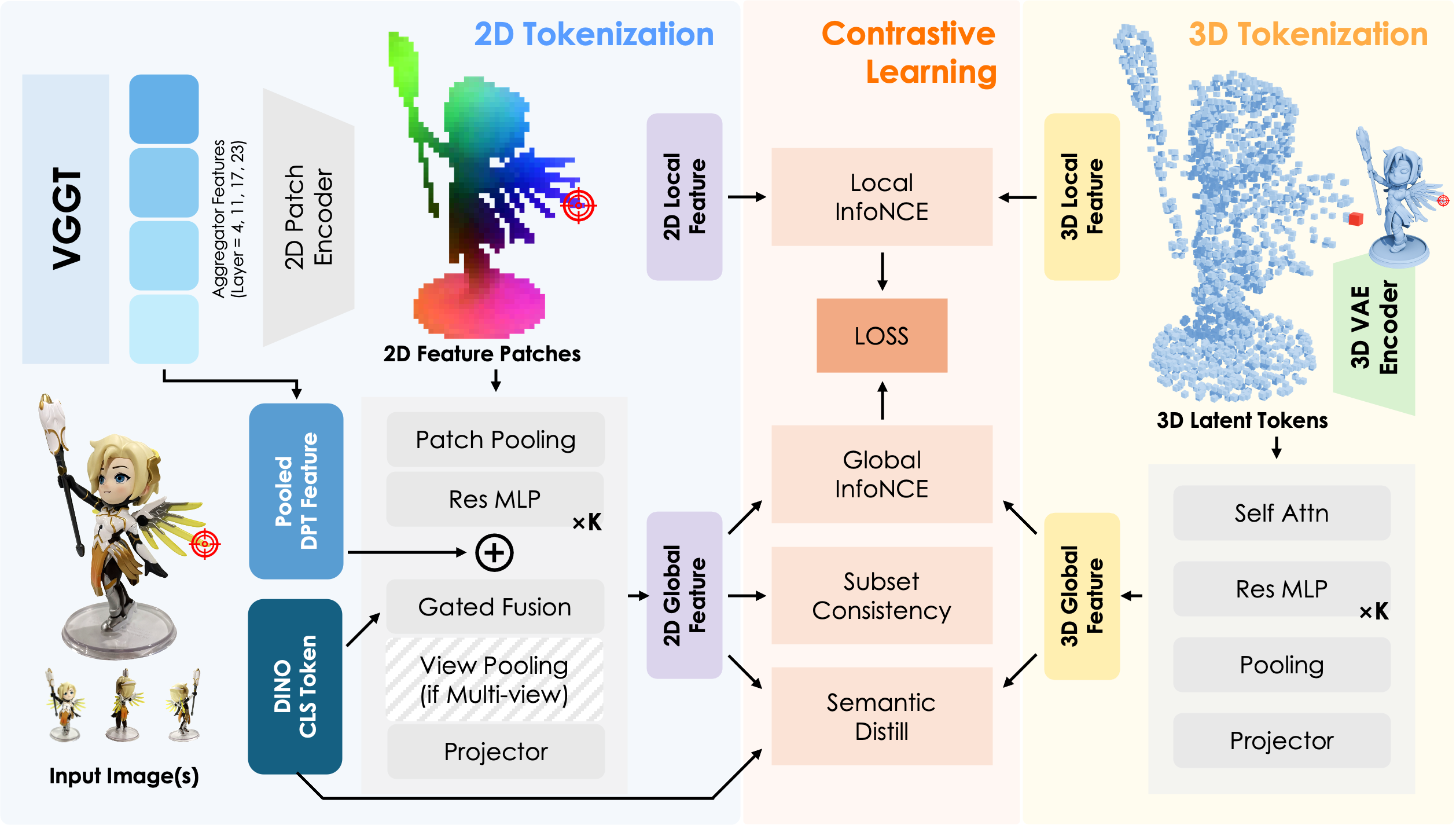
Existing 3D foundation models typically align point clouds to frozen vision-language spaces like CLIP, which achieve strong cross-modal retrieval by compressing 3D shape into a global vector. However, this global-only alignment cannot establish fine-grained pixel-to-point correspondence. To solve this, we present Tango3D, a foundation model that unifies dense correspondence and global retrieval. We use a geometry-aware 2D visual backbone and a pretrained 3D VAE to encode images into 2D patches and point clouds into 3D tokens. These are mapped into a single shared space to achieve both local pixel-to-point alignment and global semantic alignment. To stabilize the joint learning of dense and global objectives, we introduce a three-stage progressive training strategy. Experiments show Tango3D is the first to achieve object-level pixel-to-point alignment while maintaining competitive global retrieval. By establishing a fine-grained alignment feature space, Tango3D injects rich semantics into purely geometric 3D tokens, paving the way for a wide range of dense 3D downstream tasks.
A single query pixel on the 2D image accurately localizes the corresponding geometric region on the 3D mesh, confirming robust fine-grained spatial grounding.
A pixel on one object successfully retrieves the semantically equivalent 3D region on entirely different instances, indicating that the shared space captures category-level semantics rather than merely overfitting to exact shapes.
A single 3D point correctly grounds back to corresponding pixels across diverse camera poses, verifying strict multi-view consistency of the shared descriptor space.
Pure 3D-to-3D queries reveal that the 3D tokens acquire semantic part-level alignment, accurately matching corresponding structural parts across different shapes without any 2D input.
By coupling SAM with our local descriptor space, an arbitrary 2D part mask is transferred onto the 3D mesh without any part-level supervision. Click to enlarge.
Using the 2D global descriptor, Tango3D retrieves the most similar 3D shapes from a large gallery ranked by cosine similarity. Drag to rotate.
| Query Image | Top-1 | Top-2 | Top-3 | Top-4 | Last-2 | Last-1 |
|---|
Using only the 3D global descriptor without any 2D input, retrieved shapes share fine-grained geometric and topological structure beyond basic category labels. Drag to rotate.
| Query 3D | Top-1 | Top-2 | Top-3 | Top-4 | Last-2 | Last-1 |
|---|